Hebbian Learning
Task: optimize already existing FCM
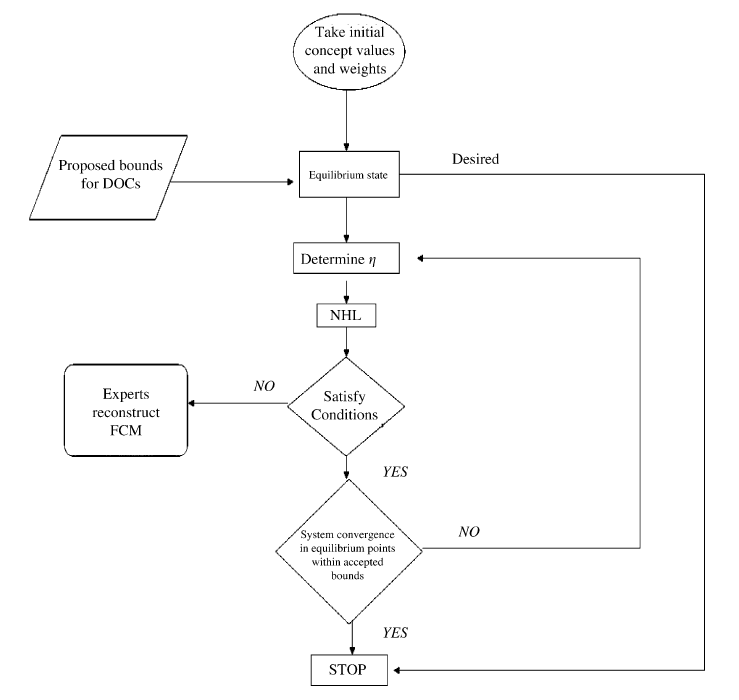
The first two methods are Nonlinear Hebbian Learning (NHL) and Active Hebbian Learning(AHL), proposed by Papageorgiou et al. Both of them are used to optimize an existing weight matrix in such a way that the chosen nodes, Desired Output Concepts (DOCs), always converge within the desired range. Both algorithms are similar to FCM simulation, with the main difference being that weights’ and concepts’ values are updated at each time step, whereas during a simulation, only the concepts values are changing. For the NHL algorithm, all nodes (Ai) and weights (Wij - a direct edge from node i to j) values are simultaneously updated at each time step. In AHL, nodes and weights are updated asynchronously. During each time step, a new node becomes an ''activated node'' and only that node and edges pointing to it are being updated and all the other ones remain constant. Along with optimizing existing edges, AHL creates new connections between the concepts, which may be an undesirable behavior in some cases.
For more information about the algorithms, please check out Unsupervised learning techniques for fine-tuning fuzzy cognitive map causal links by Elpiniki I. Papageorgiou, Chrysostomos Stylios, Peter P. Groumpos
First import all necessar libraries and fix randomnessfrom fcmpy.ml.hebbian.runner import simulator
import numpy as np
W_init = np.asarray([[0,-0.4,-0.25,0,0.3],[0.36,0,0,0,0],[0.45,0,0,0,0],[-0.9,0,0,0,0],[0,0.6,0,0.3,0]])
A0 = np.asarray([0.4,0.707,0.607,0.72,0.3])
# Define DOC - concepts which values we want to stay within the desired range
doc = {0:[0.68,0.74],4:[0.74,0.8]}
%%capture
records = []
for lbd in np.arange(0.9,1.01,0.01):
for decay in np.arange(0.95,1.0,0.01):
for learning_rate in np.arange(0.001,0.1,0.001):
# Running the NHL algorithm for chosen hyperparameters, appending generated weight matrix if the algorithm converged
run = simulator('nhl', learning_rate=learning_rate,decay=decay, A0=A0, W_init= W_init, doc=doc,lbd = lbd)
if run is not None:
records.append(run)
%%capture
recordsahl = []
# for lbd in np.arange(0.9,1.01,0.01):
lbd = 1
for decay in np.arange(0.01,0.1,0.01):
for learning_rate in np.arange(0.001,0.1,0.001):
# Running the AHL algorithm for chosen hyperparameters, appending generated weight matrix if the algorithm converged
run = simulator('ahl', learning_rate=learning_rate,decay=decay, A0=A0, W_init= W_init, doc=doc, lbd = lbd)
# we do this loop for a particular initiated learning rate
if run is not None:
recordsahl.append(run)