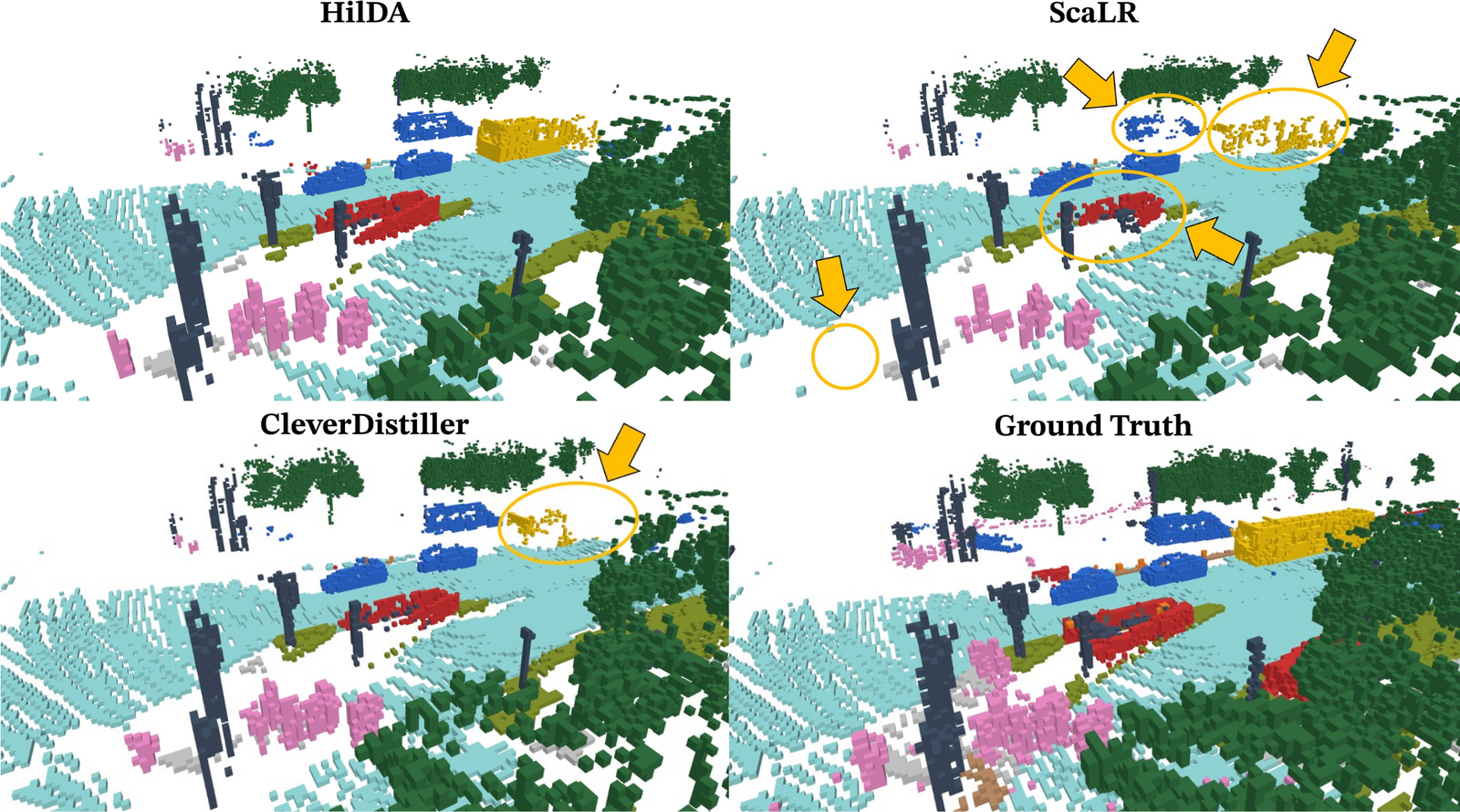
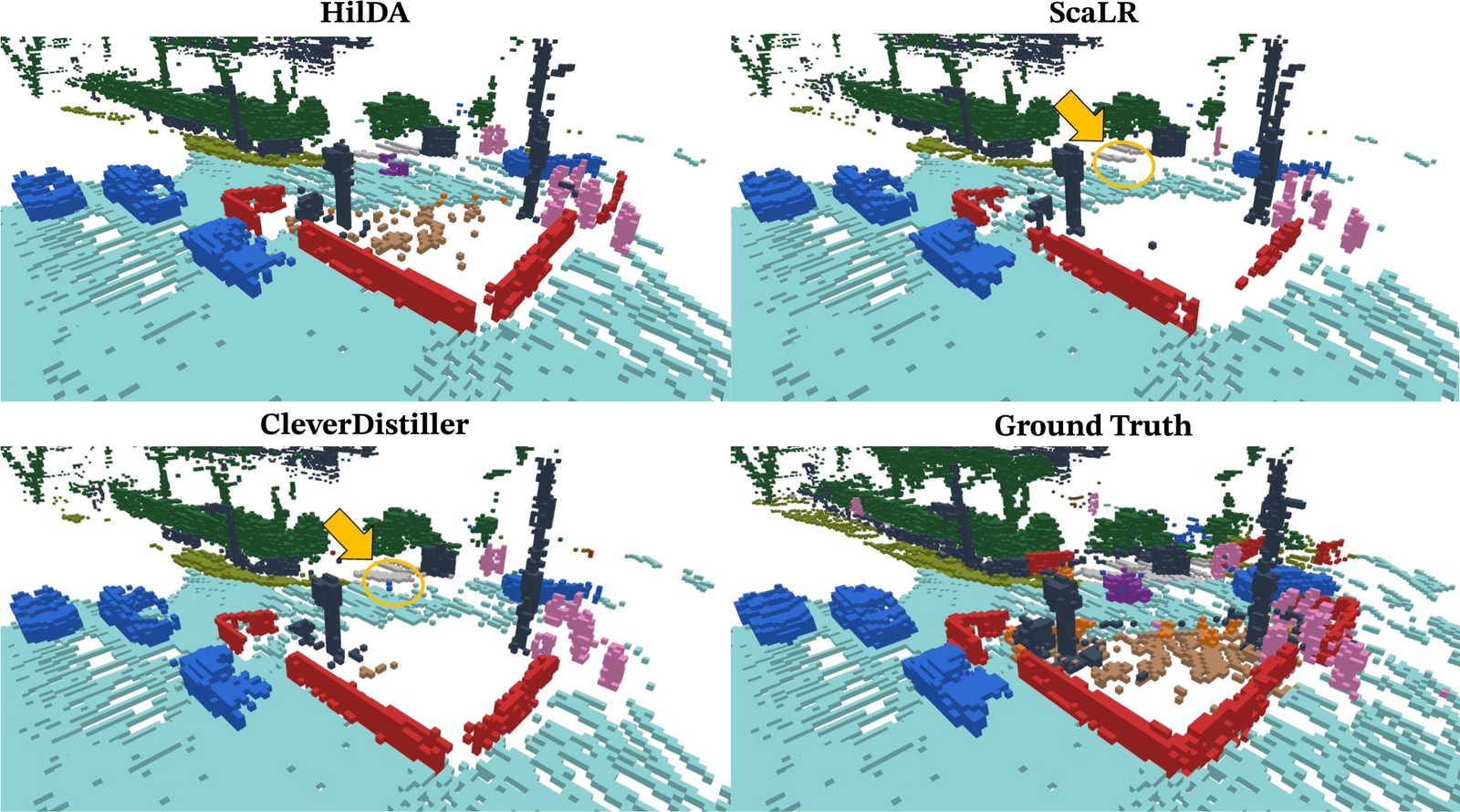
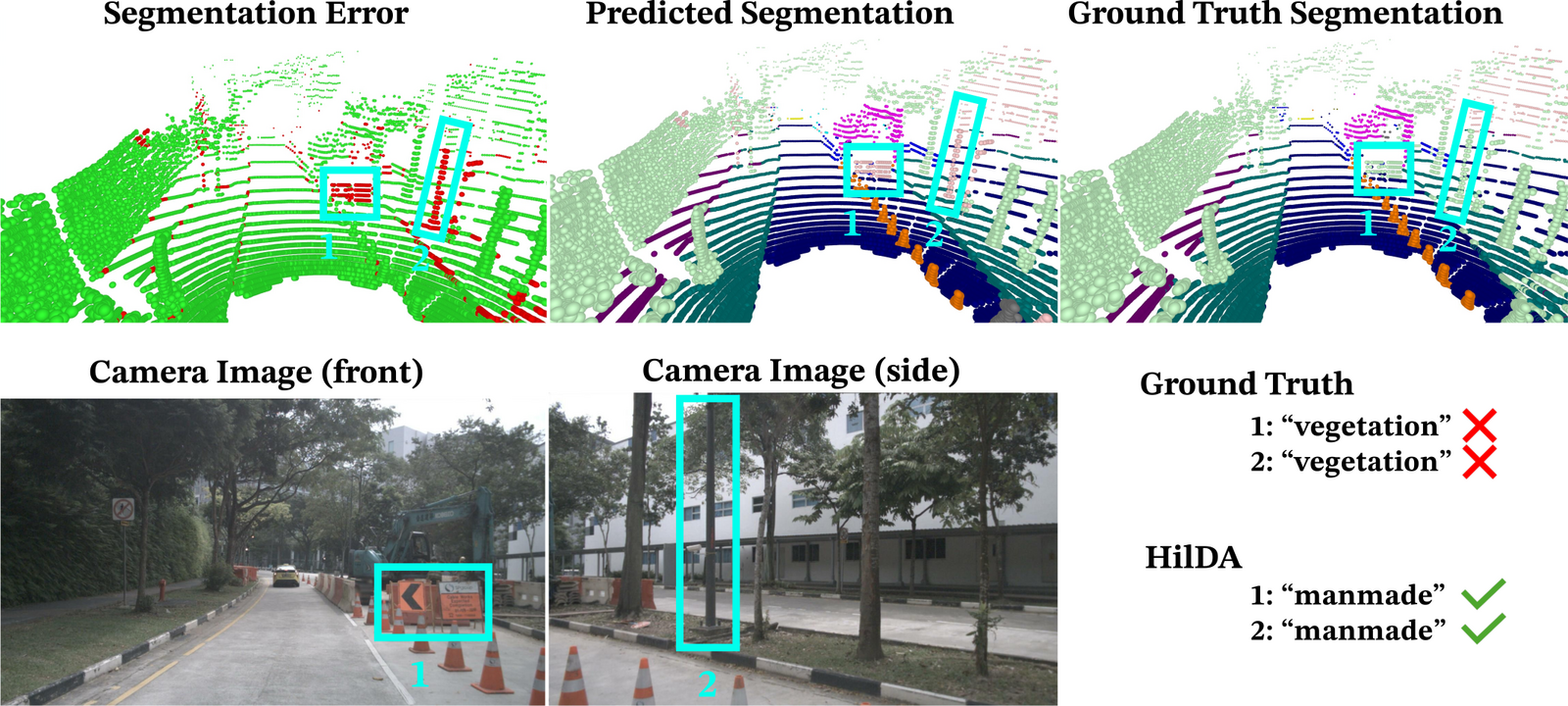
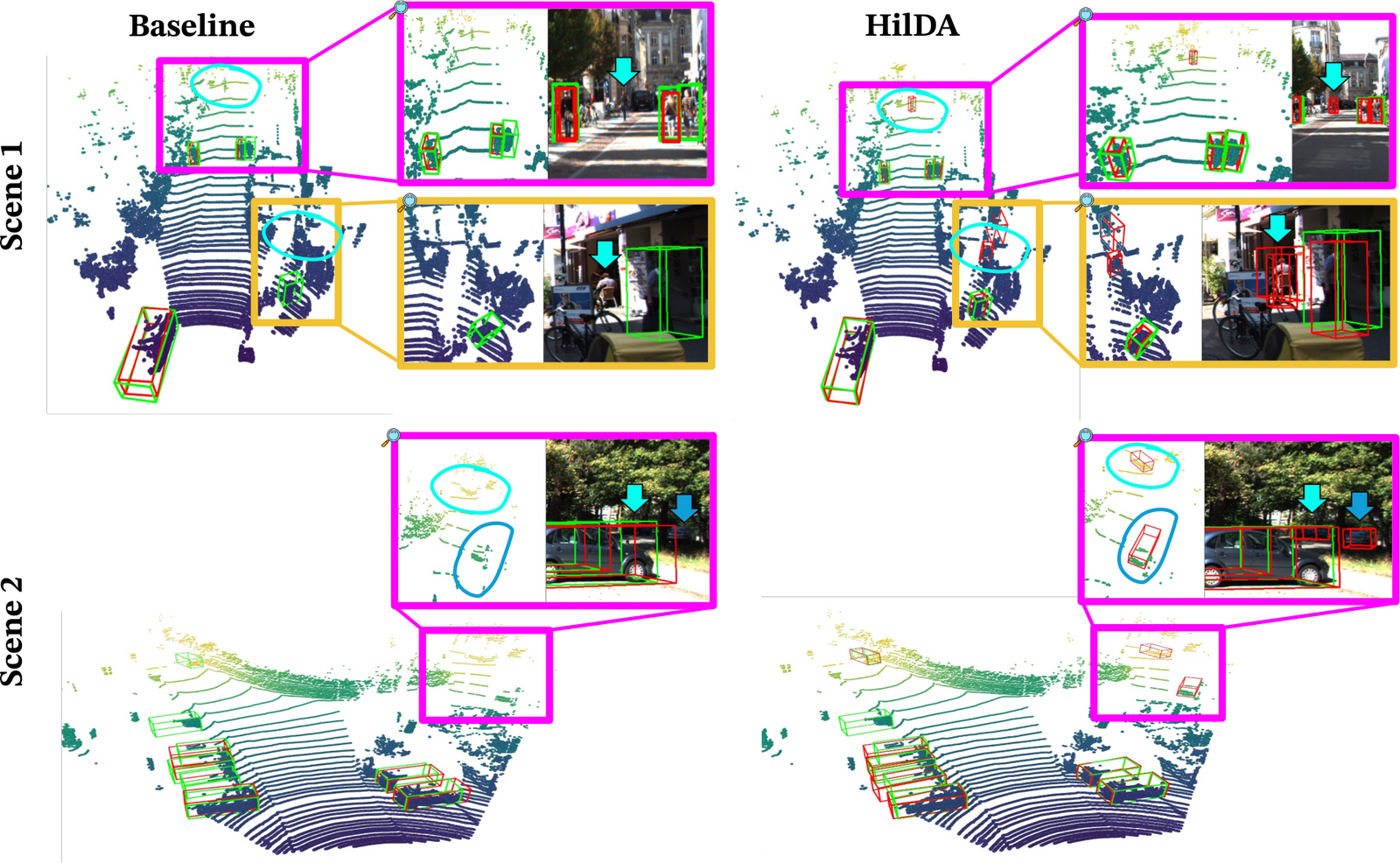
Vision Foundation Models (VFMs) are powerful teachers for camera-to-LiDAR knowledge
distillation, helping LiDAR backbones learn rich semantics without manual labels.
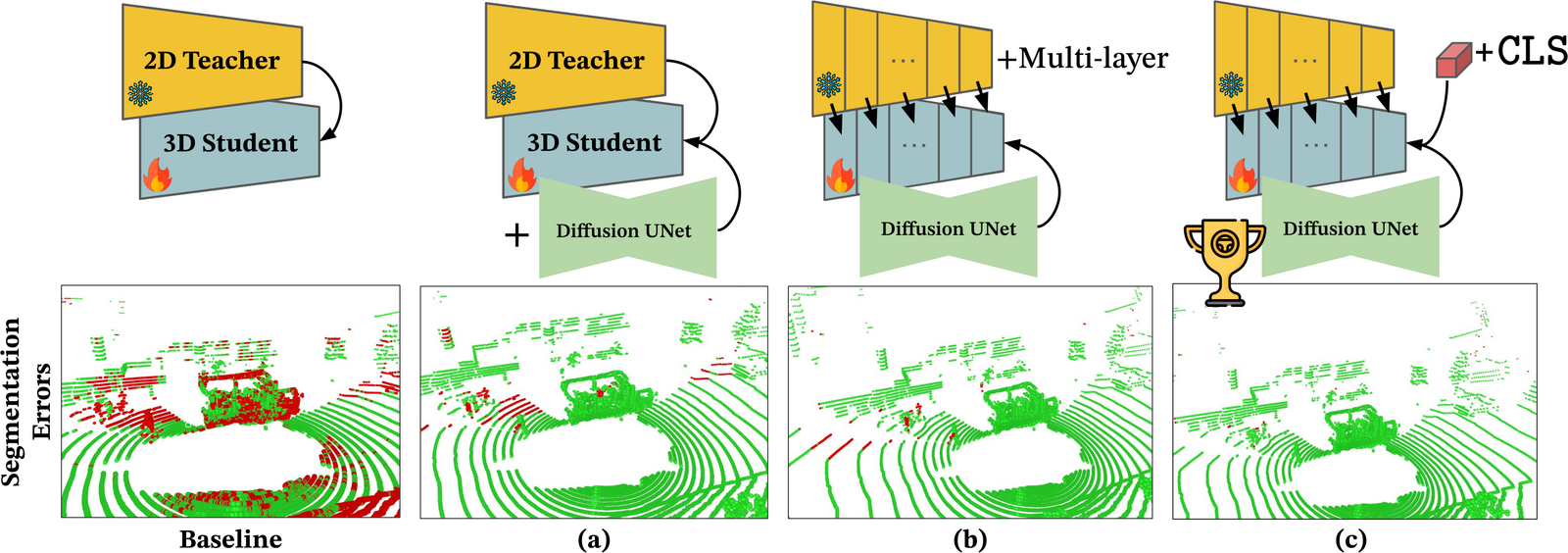
Yet current methods treat VFMs as black boxes — distilling only frame-wise features
from the final layer, and ignoring both the teacher's layer-wise semantic
structure and the spatiotemporal information in LiDAR sequences.
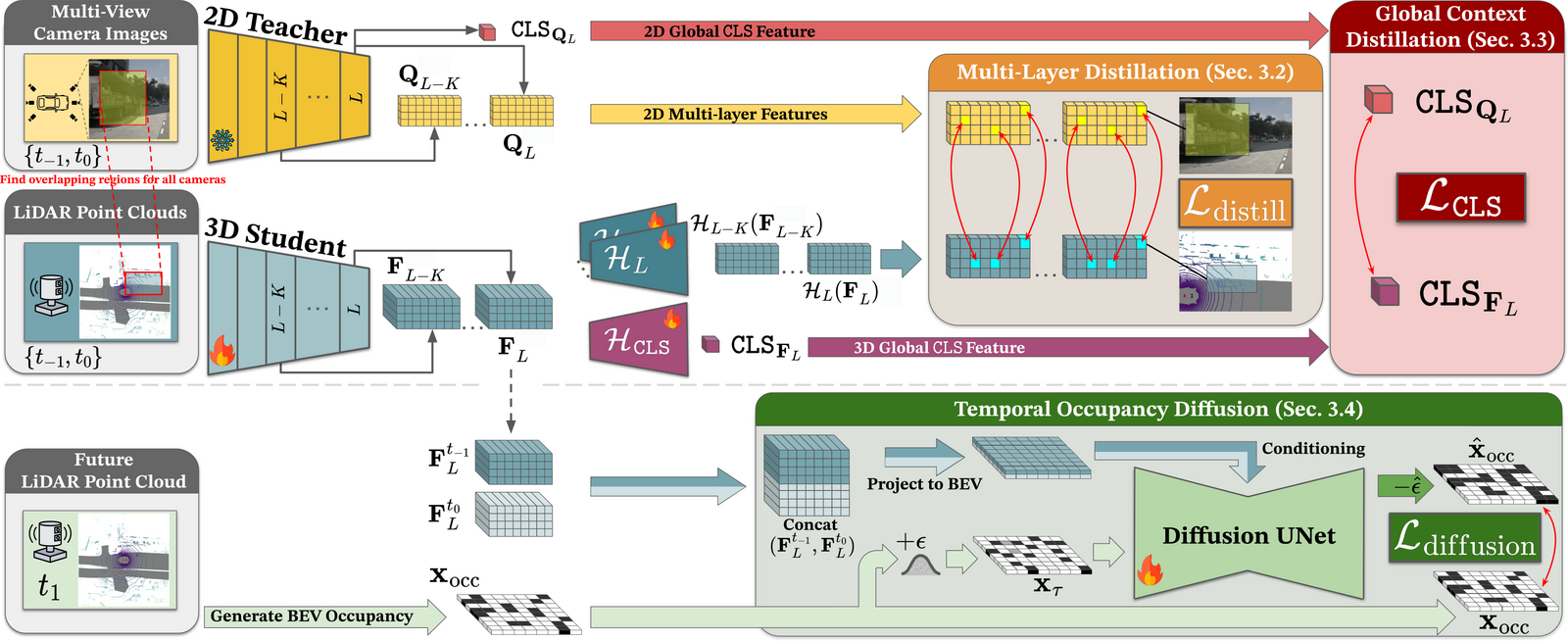
We propose HilDA, a self-supervised pre-training framework that captures both the
semantic what and the geometric where needed for driving. HilDA combines
hierarchical distillation — multi-layer distillation for progressive semantic
alignment plus global context distillation for scene-level semantics — with a
temporal occupancy diffusion objective that enforces spatiotemporal consistency.
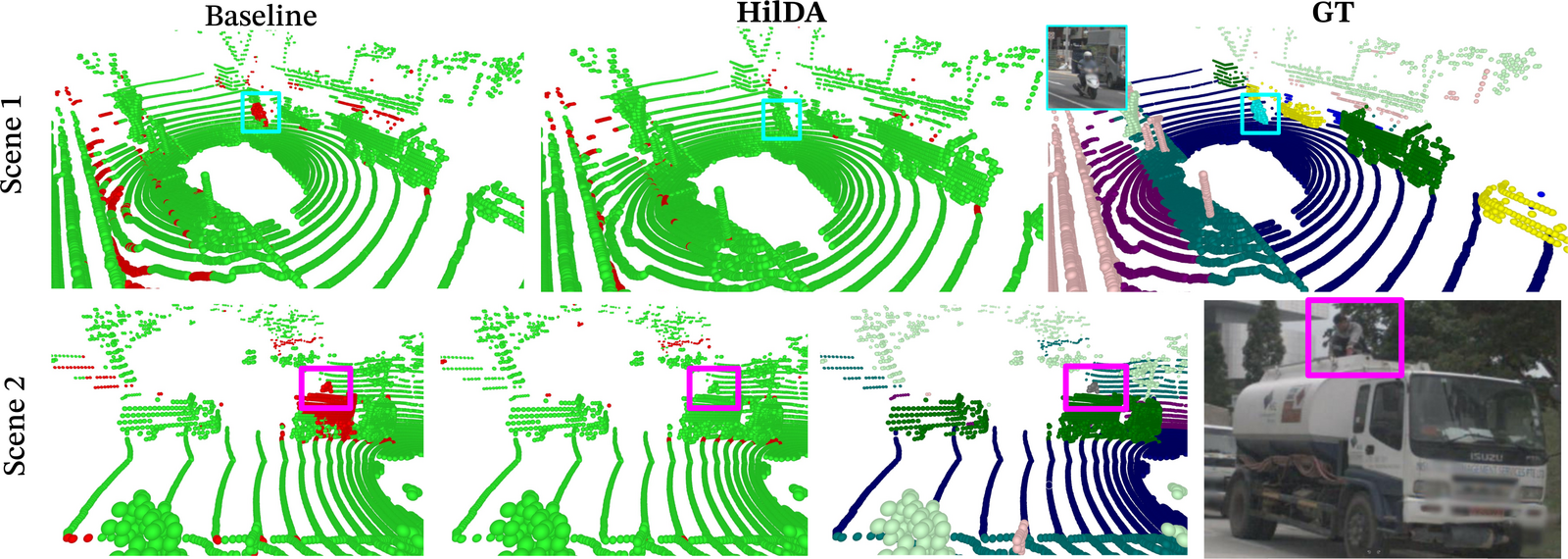
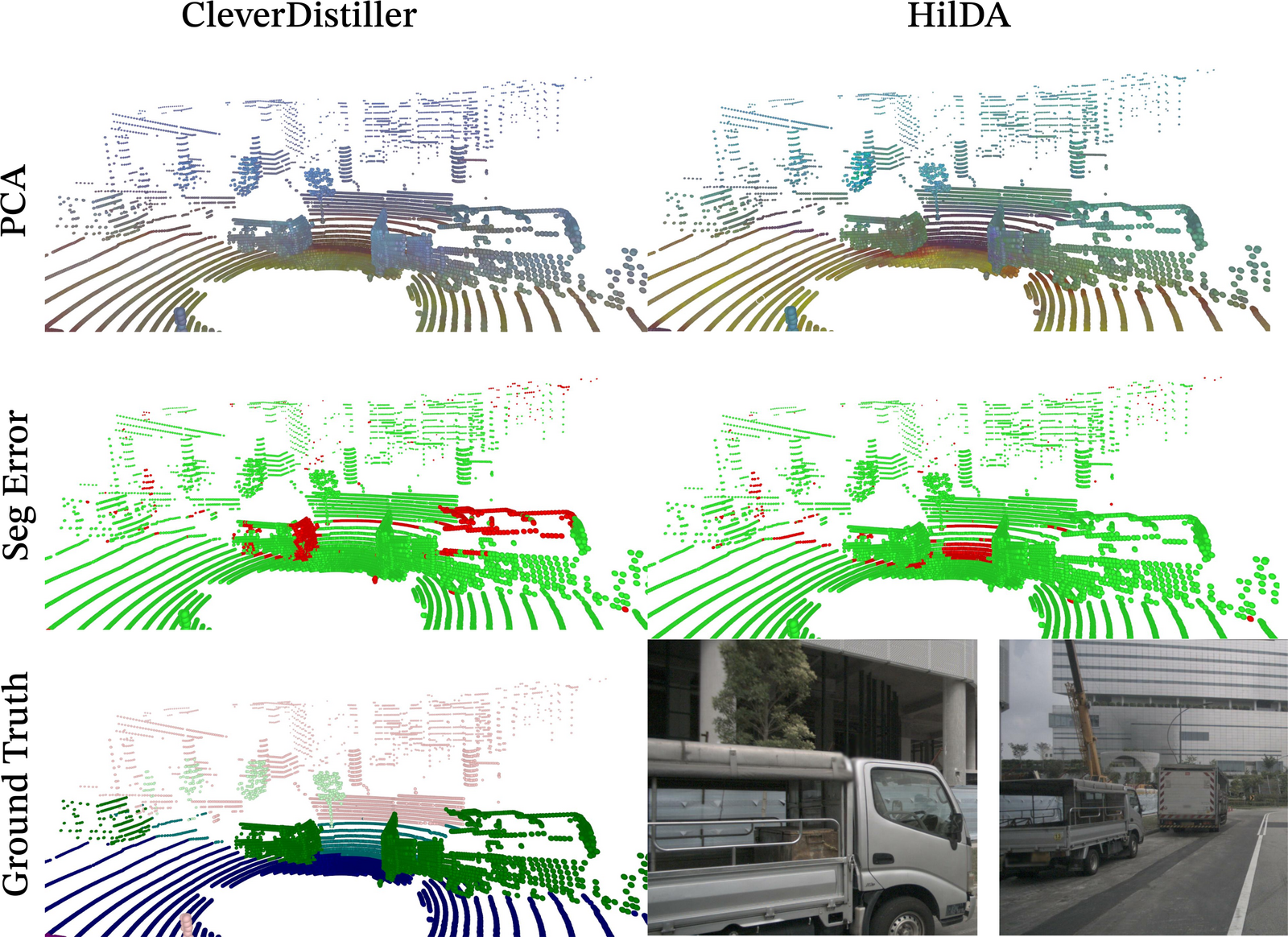
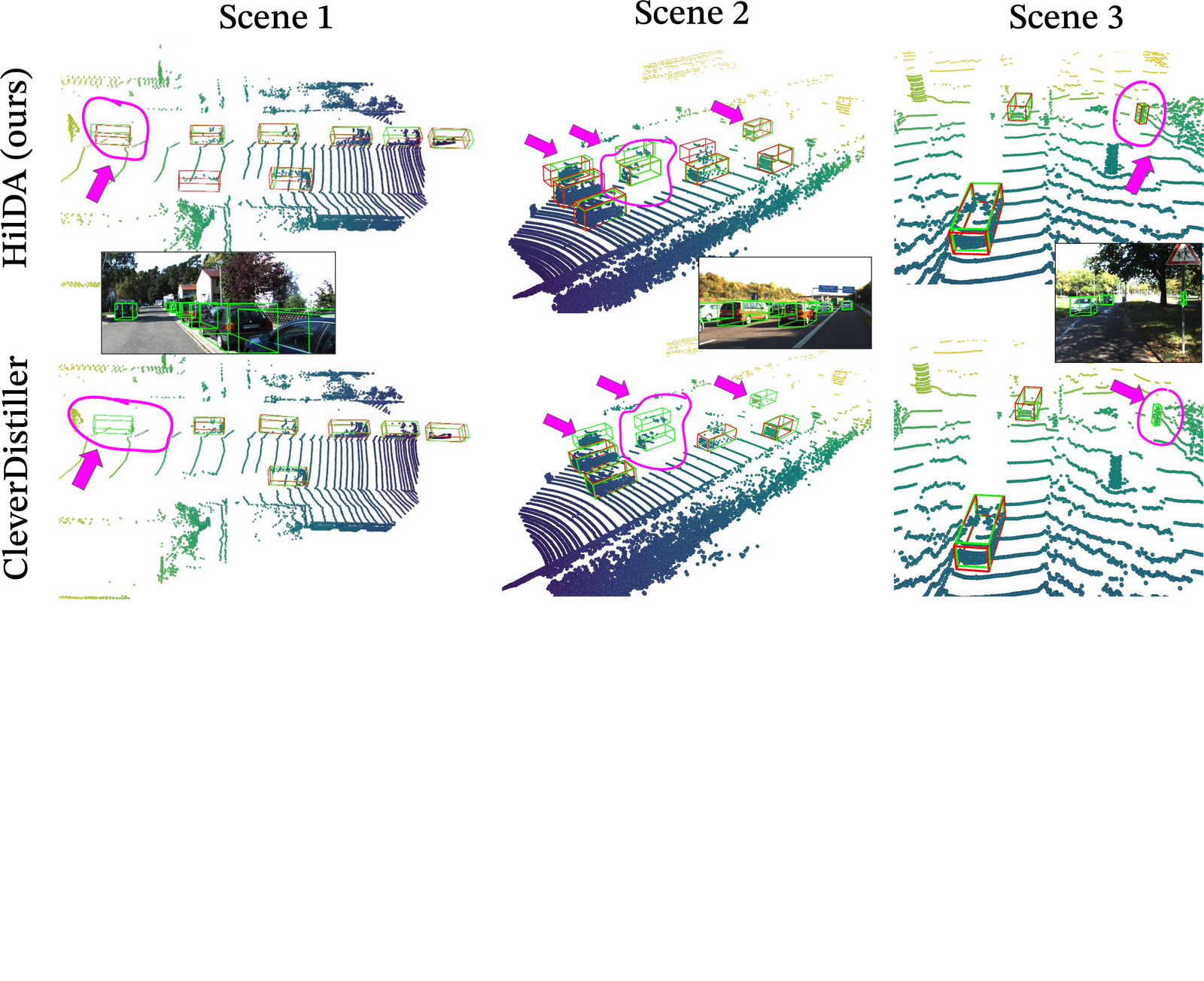
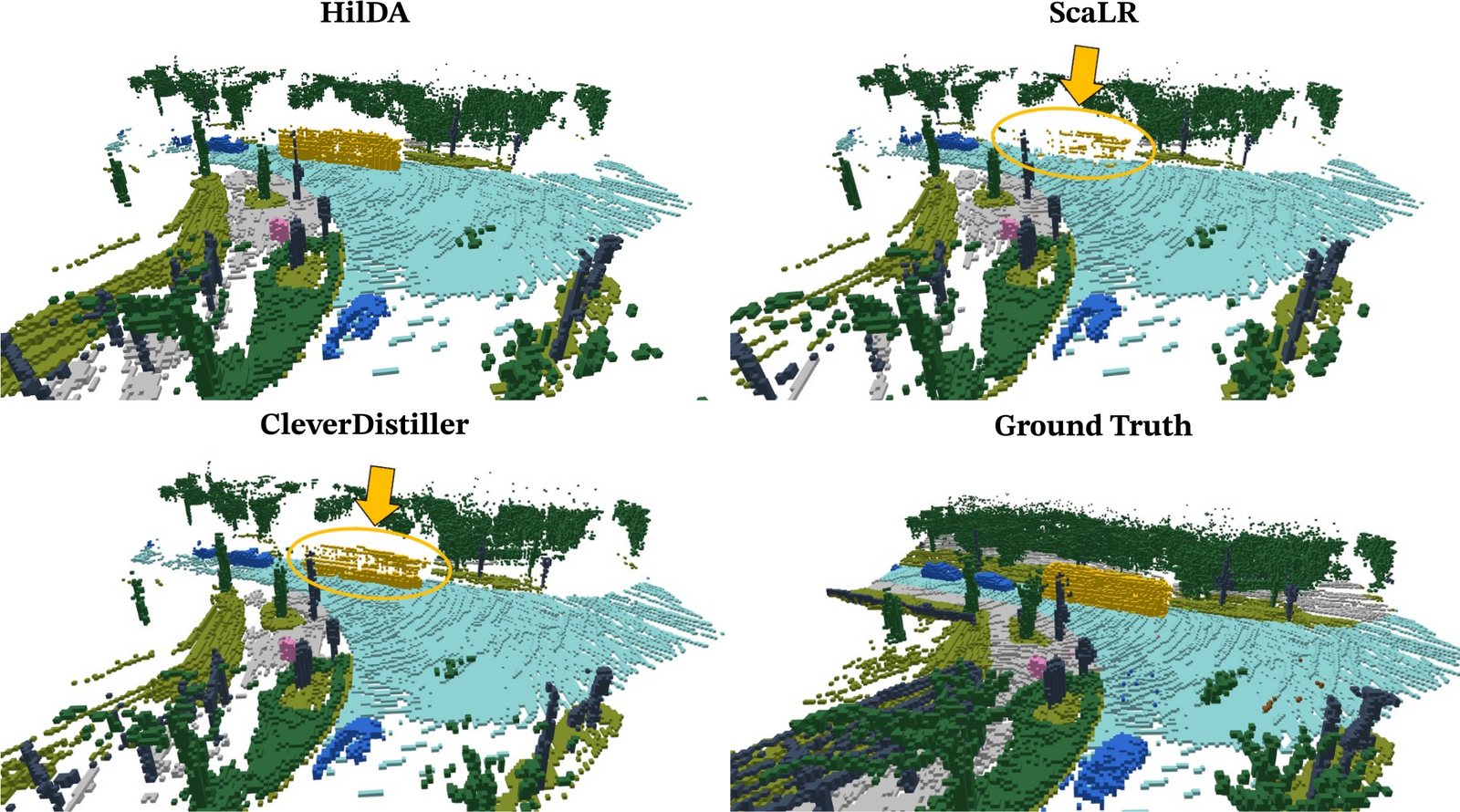
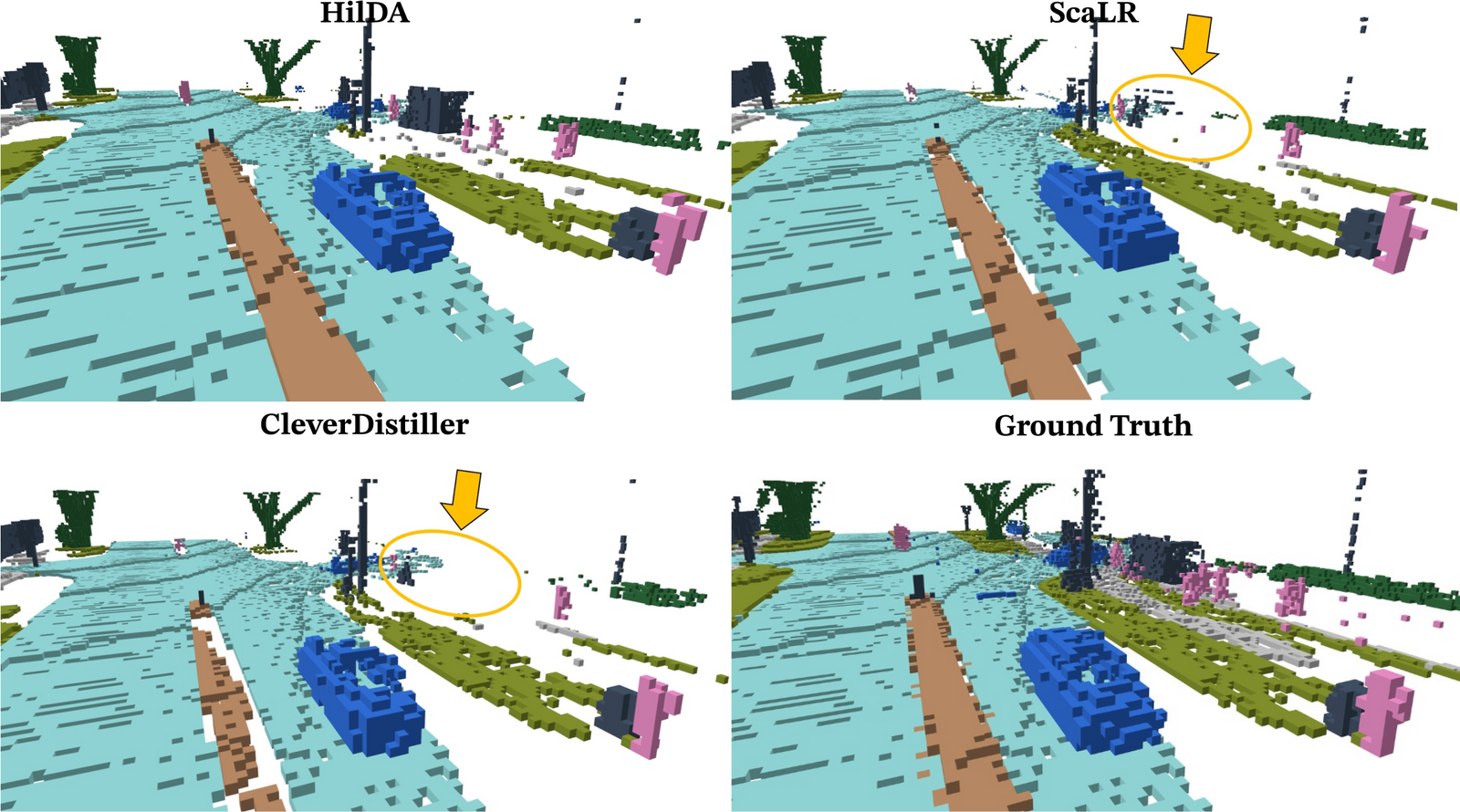
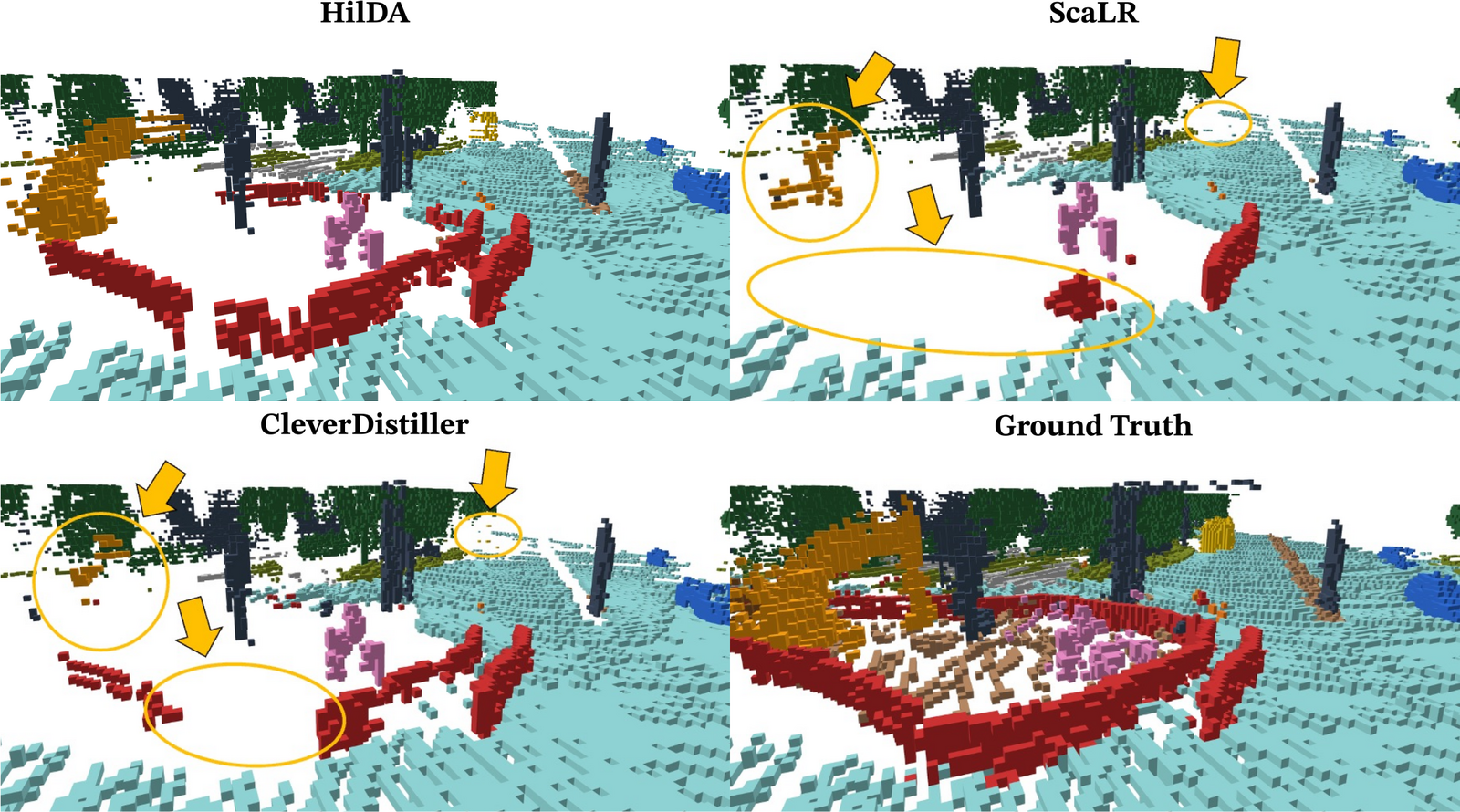
Models pre-trained with HilDA reach state-of-the-art results on cross-modal distillation
benchmarks and outperform prior distillation methods on 3D detection, scene flow, and
semantic occupancy prediction.