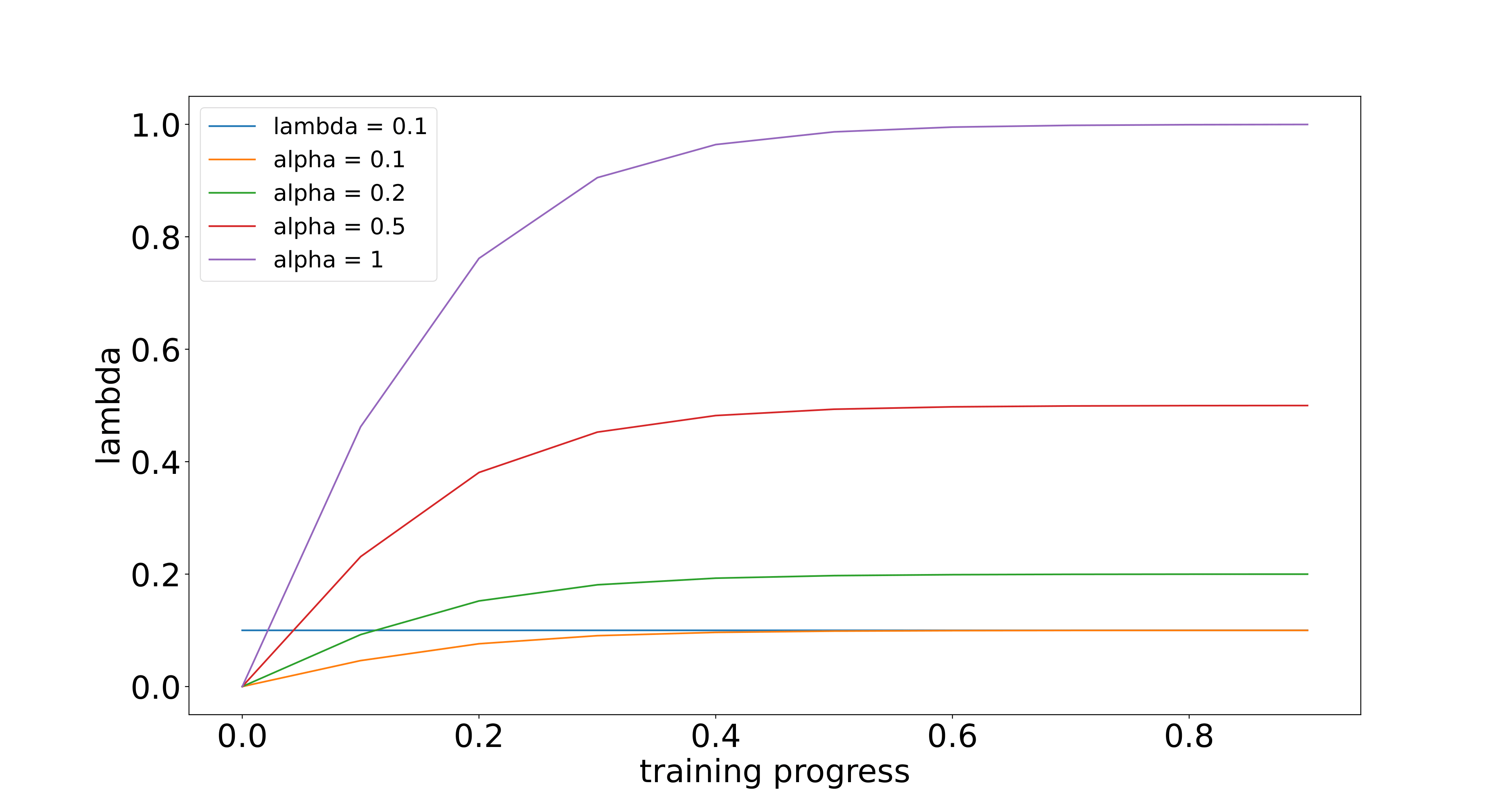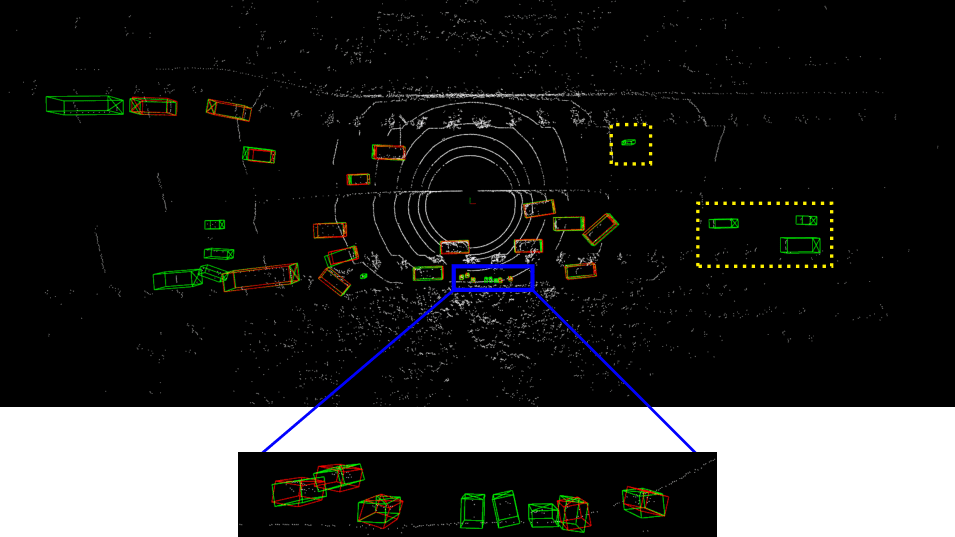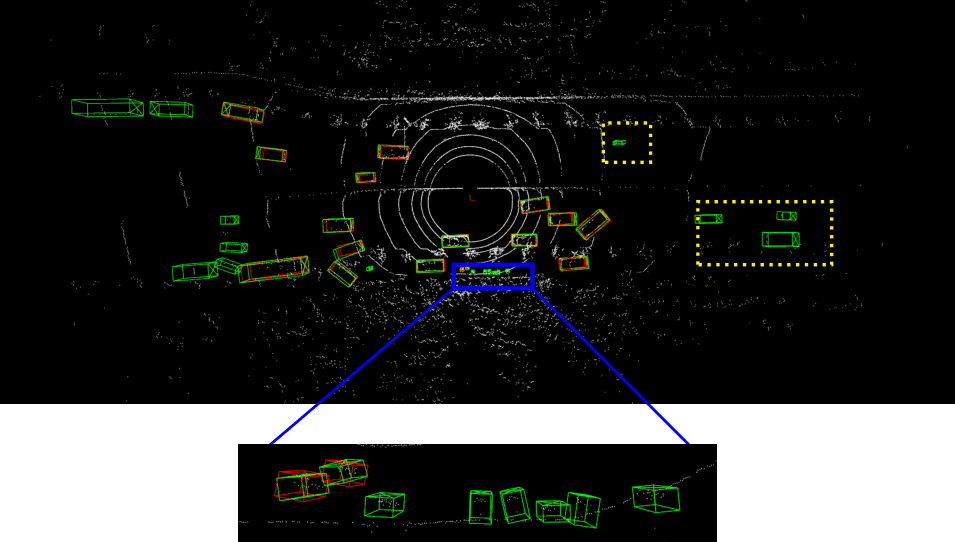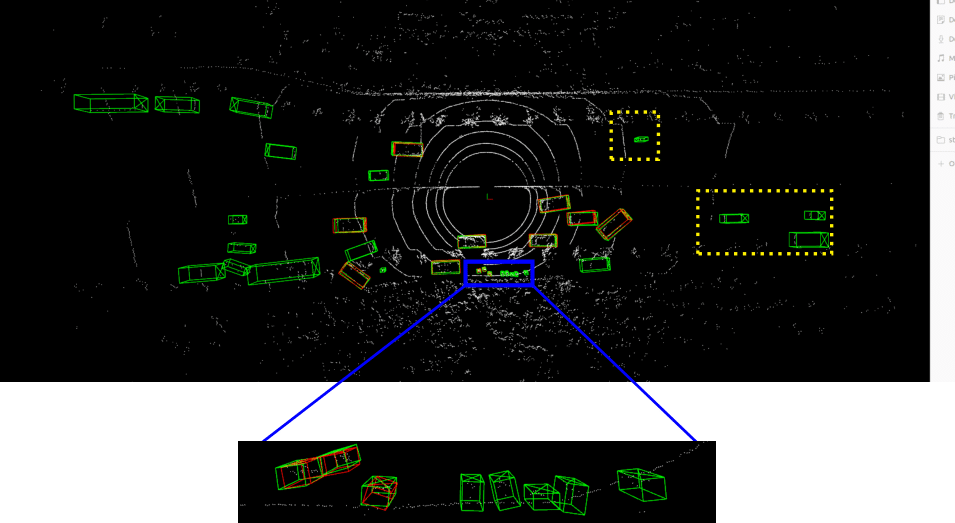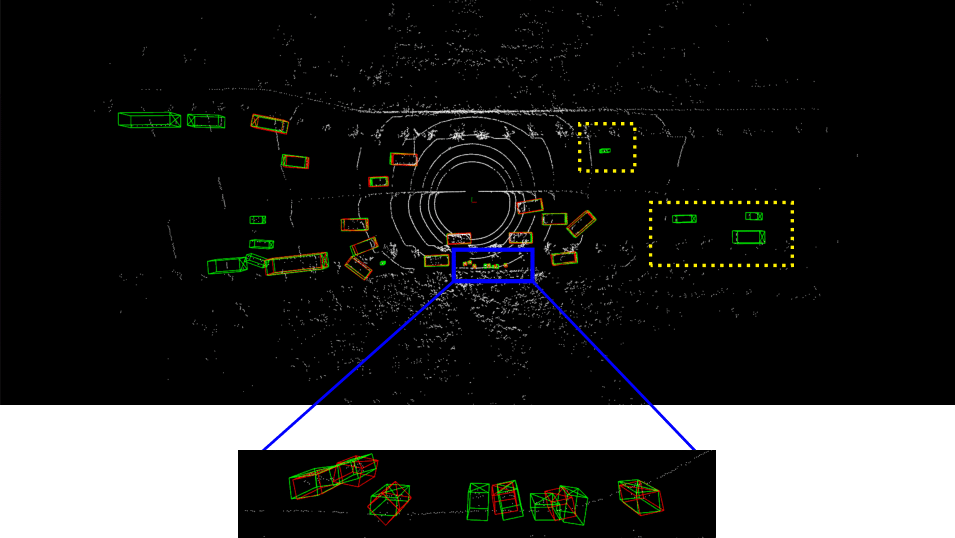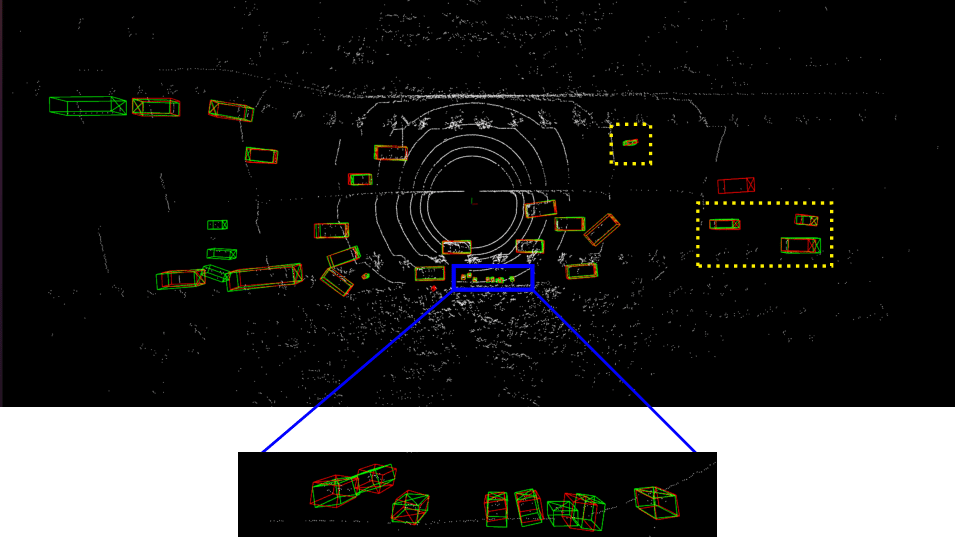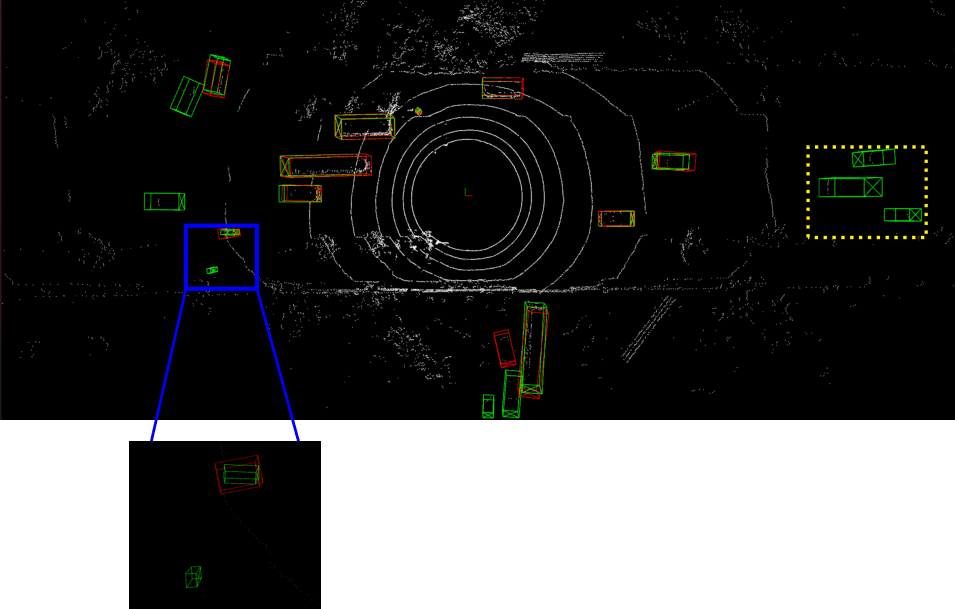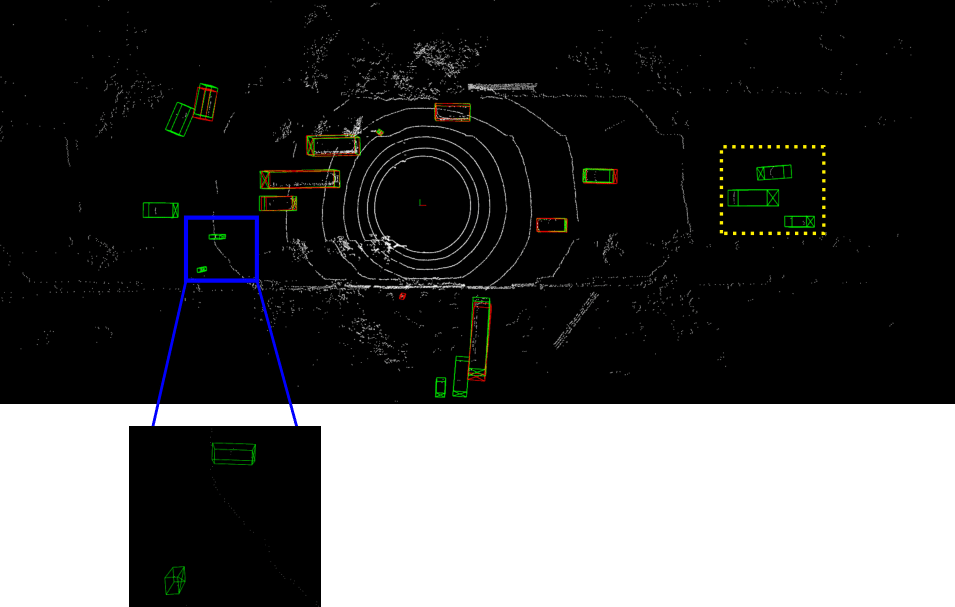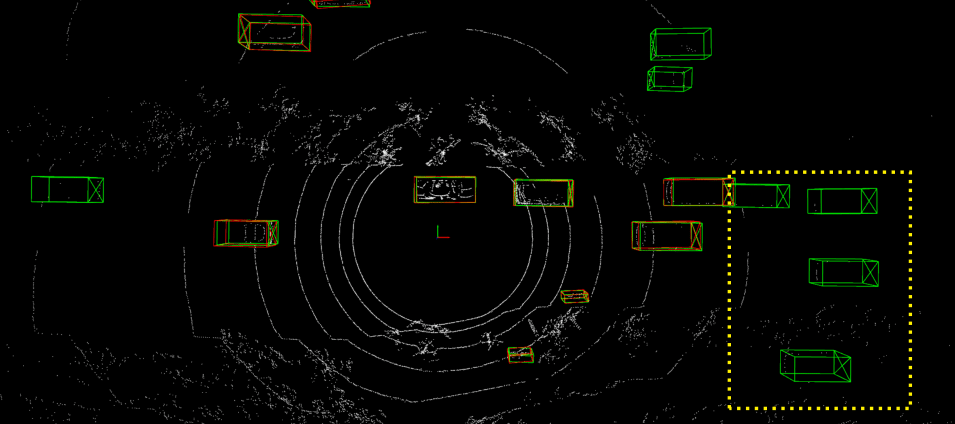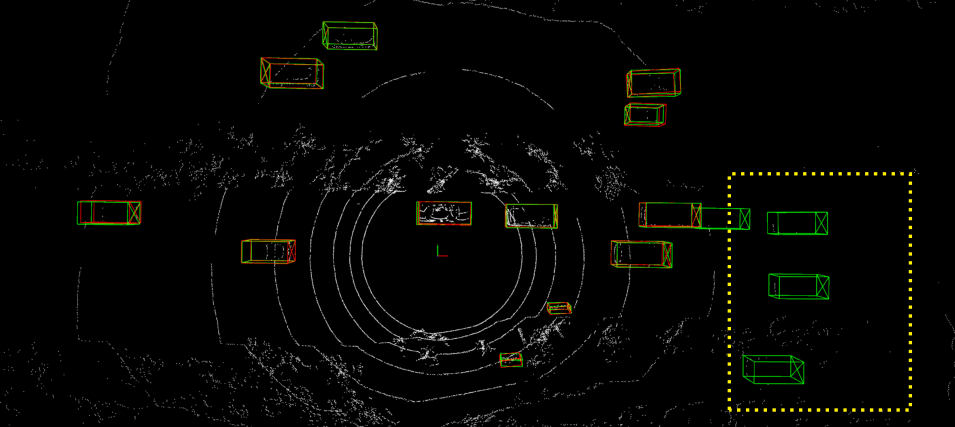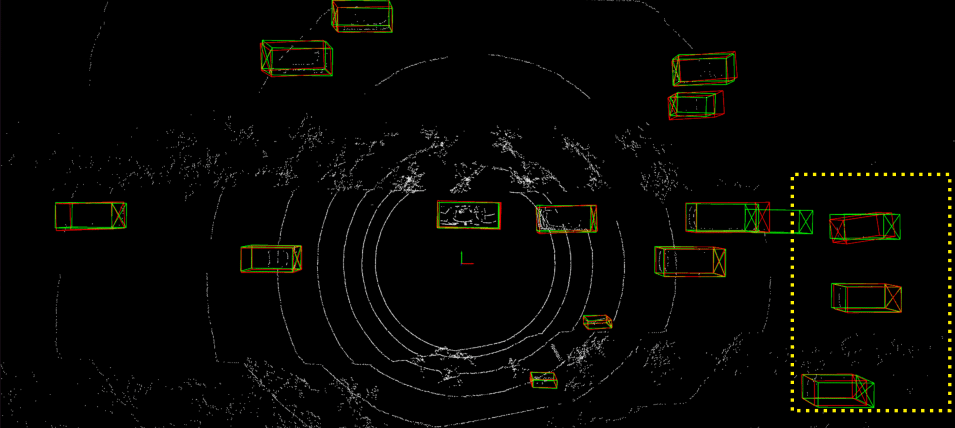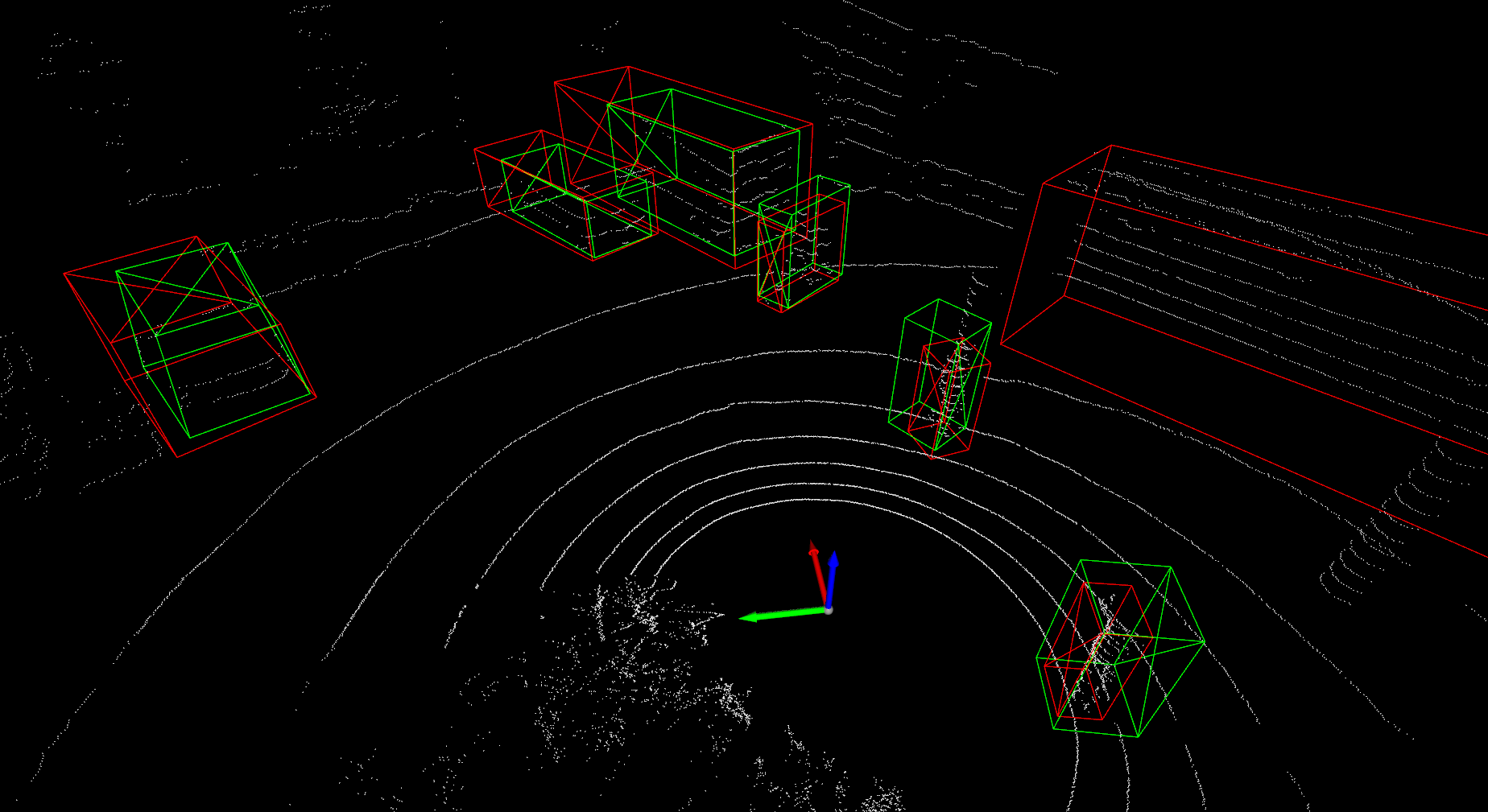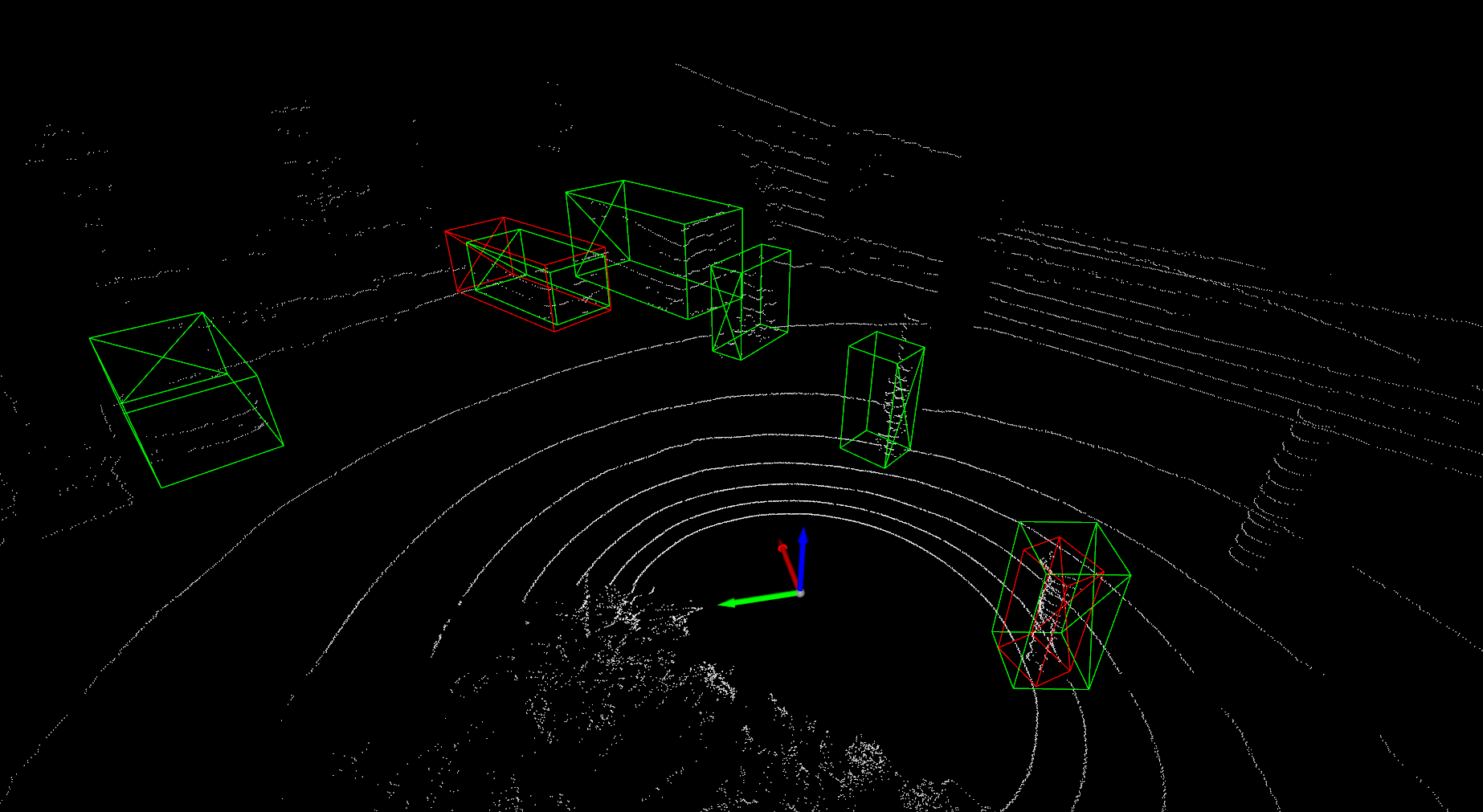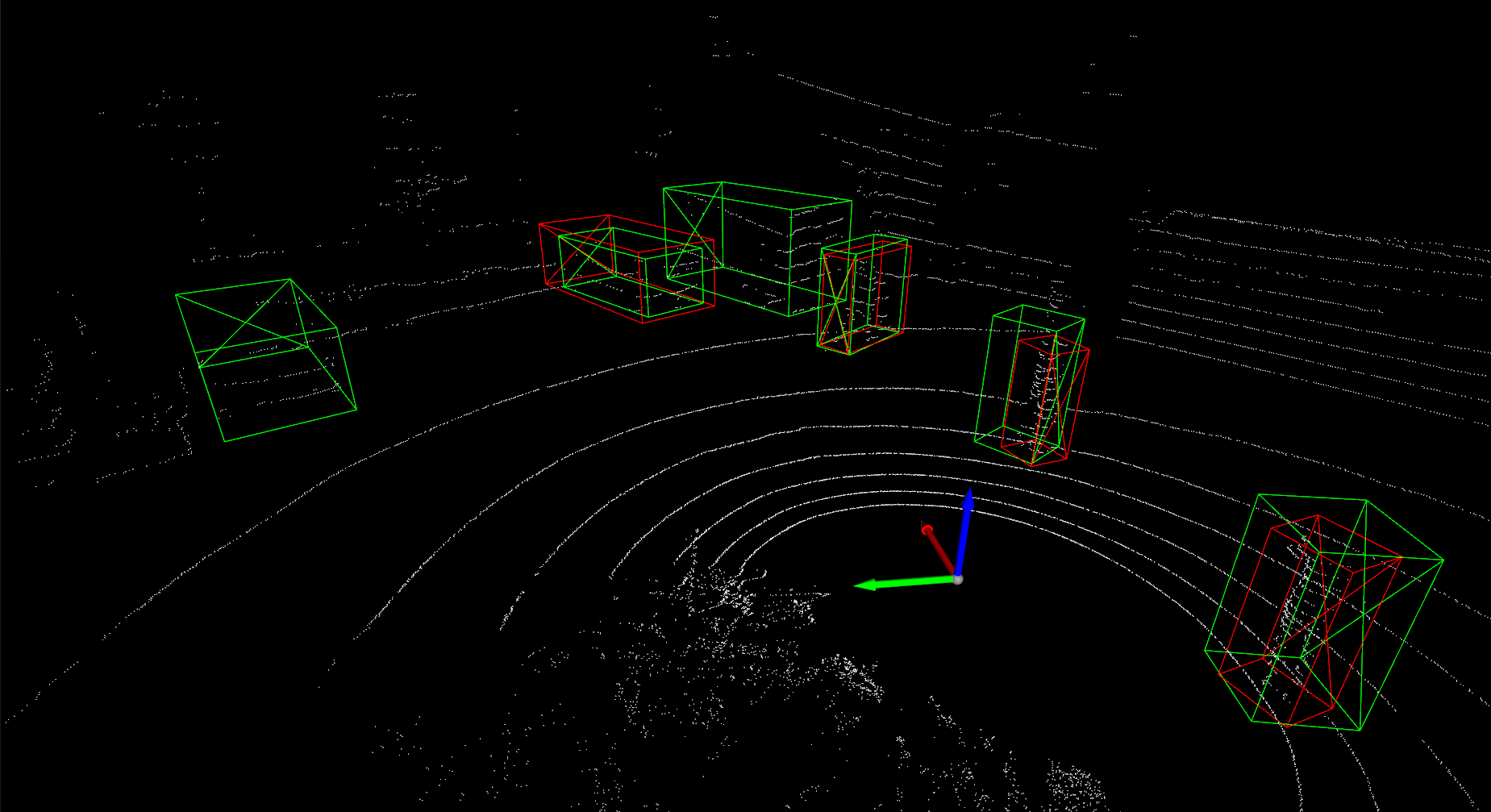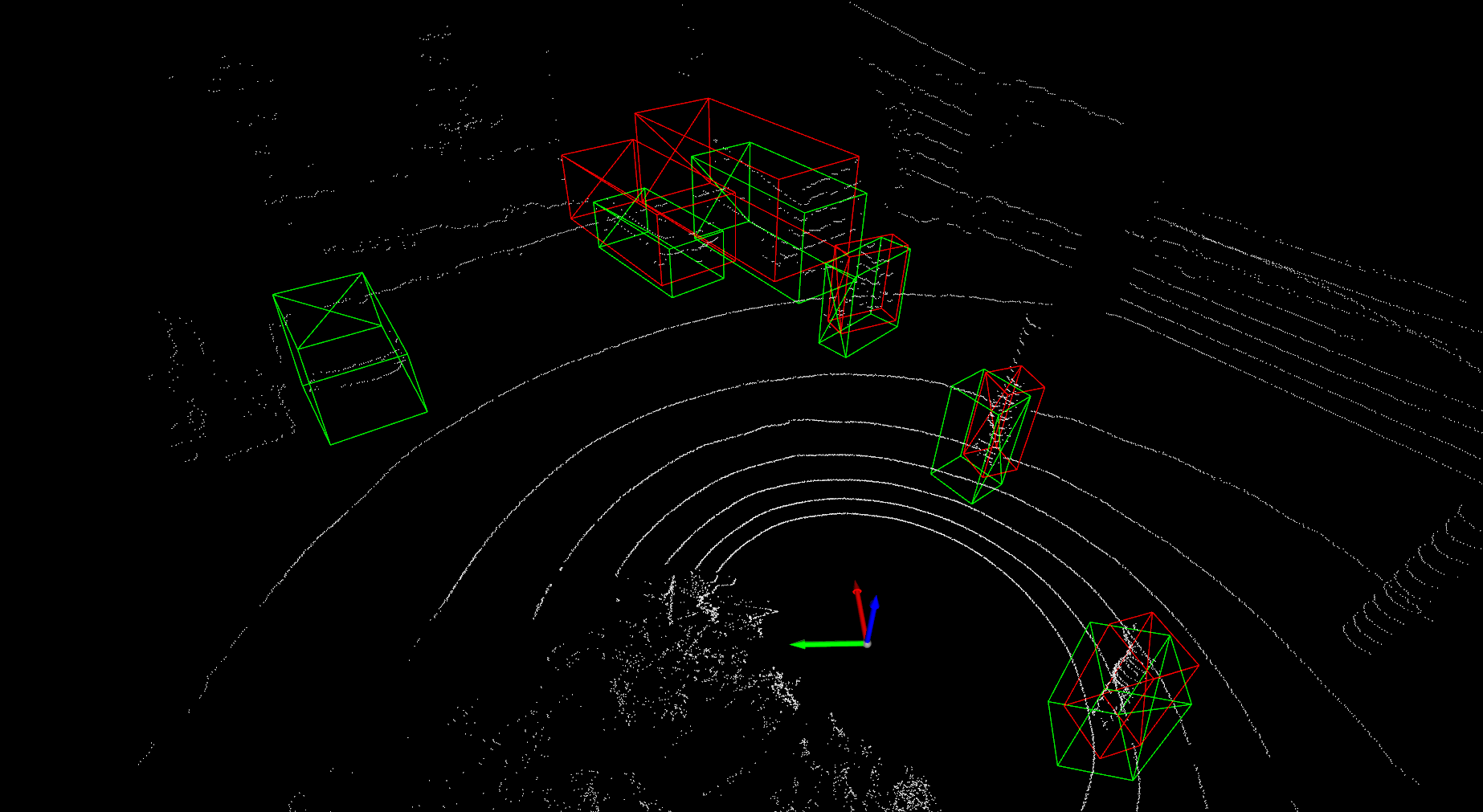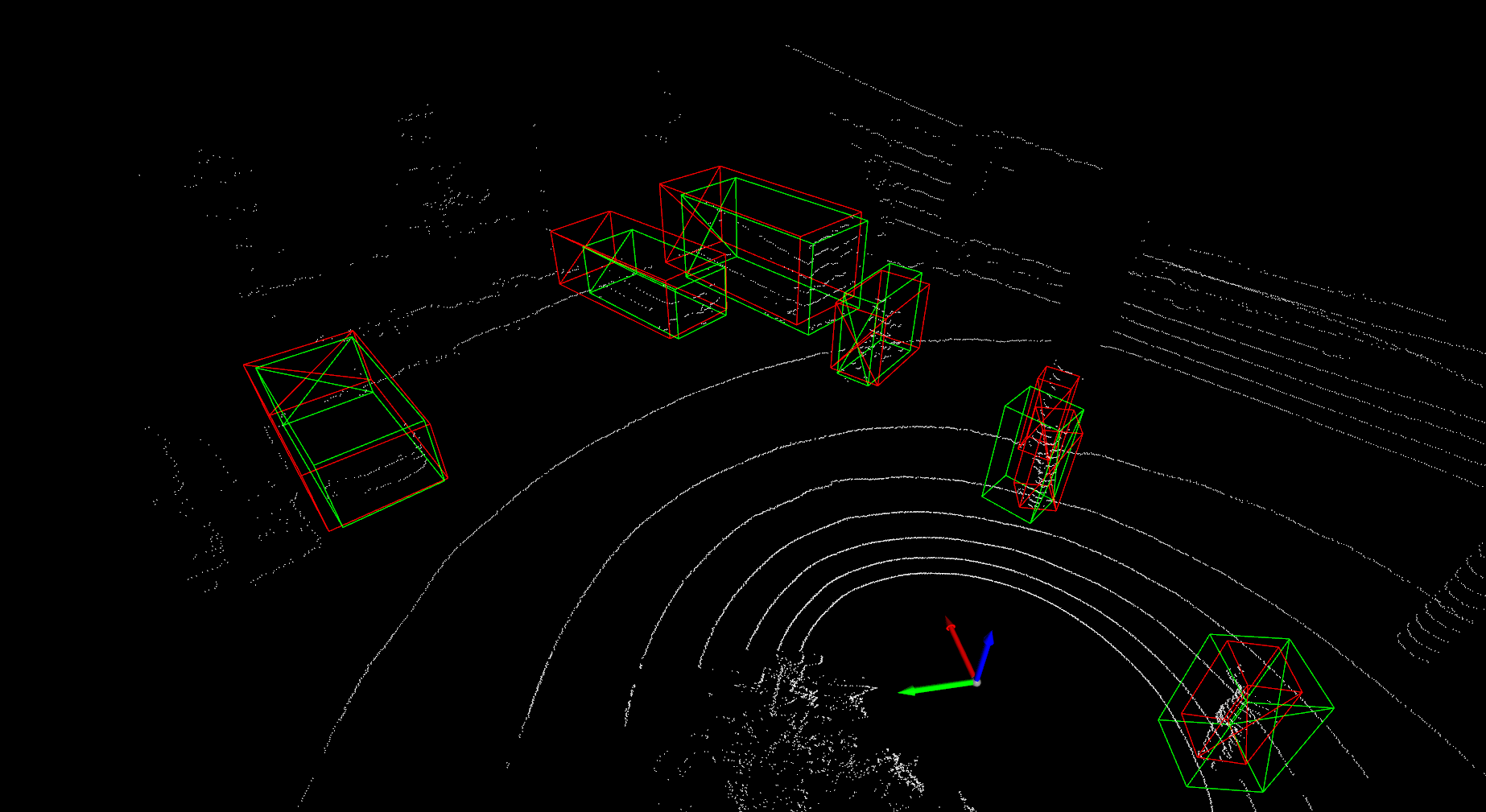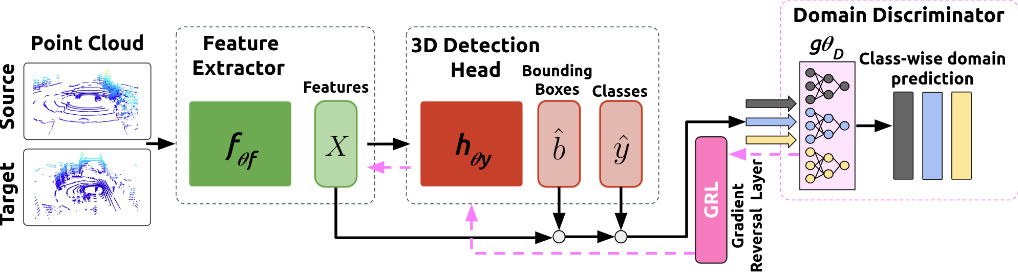
Detailed implementation of UADA3D The conditional module has the task of reducing the discrepancy between the condi- tional label distribution P (Ys|Xs) of the source and P (Yt|Xt) of the target. The label space Yi consists of class labels y ∈ RN ×K and 3D bounding boxes bi ∈ R7. The feature space X consists of point features F ∈ RN ×C (IA-SSD) or the 2D BEV pseudo- image I ∈ Rw×h×C (Centerpoint). The domain discriminator gθD in Centerpoint has 2D convolutional layers of 264, 256, 128, 1 while IA-SSD uses an MLP with dimensions 519, 512, 256, 128, 1. LeakyReLU is used for the activation functions with a sigmoid layer for the final domain prediction. A kernel size of 3 was chosen for Centerpoint, based on experiments shown in B.4. Note, that we do class-wise domain prediction, thus we have K discriminators corresponding to the number of classes (in our case K = 3, but it can be easily modified).
Detailed implementation of UADA3DLm The primary role UADA3DLm with the marginal feature discriminator is to minimize the discrepancy between the marginal feature distributions of the source, denoted as P(Xs), and the target, represented by P(Xt). Here, Xs and Xt symbolize the features extracted by the detection backbone from the two distinct domains. This approach ensures the extraction of domain invariant features. The loss function of UADA3DLm marginal alignment module is defined through Binary Cross Entropy. The output of the point-based detection backbone in IA-SSD is given by N point features with feature dimension C and corresponding encodings. Point-wise discriminators can be utilized to identify the distribution these points are drawn from. The input to the proposed marginal discriminator \( g_{\theta_D} \) is given by point-wise center features obtained through set abstraction and downsampling layers. The discriminator is made up of 5 fully connected layers (512,256,128,64,32,1 ) that reduce the feature dimension from C to 1 . LeakyReLU is used in the activation layers and a final sigmoid layer is used for domain prediction. The backbone in Centerpoint uses sparse convolutions to extract voxel-based features that are flattened into 2D BEV-features. Therefore, the input to the view-based marginal discriminator is given by a pseudo image of feature dimension C with spatial dimensions \(w\) and \(h\) that define the 2D BEV-grid. Since 2D convolutions are more computationally demanding over the MLP on the heavily downsampled point cloud in IA-SSD">IA-SSDDLm, the 2D marginal discriminator uses a \(3\)-layered CNN that reduces the feature dimension from C to 1 (256,256,128,1), using a kernel size of 3 and a stride of 1. Same as in the point-wise case, the loss function of UADA3DLm is defined through Cross Entropy.